Panorama-Sampler for Oracle databases
'Panorama-Sampler' is an add-on function for Panorama which allows it's own database workload recording as alternative to use of AWR data.This enables you to use Panorama's functions for evaluation of historic workload info:
- with any database edition including Standard Edition
- without licensing of Diagnostics Pack for Enterprise Edition

Functions
Panorama-Sampler delivers several functions for recording of historic workload information- Replacement for Active Workload Repository (AWR) and Active Session History (ASH)
- Sampling of storage object sizes
- Sampling of DB-cache usage by objects
- Sampling of detailed blocking lock information
- Long-term storage of condensed Active Session History
Usage
Configure your Panorama server instance for Panorama-Sampler
- You enable Panorama-Sampler by starting the Panorama application with a master-password for Panorama-Sampler provided by environment variable PANORAMA_MASTER_PASSWORD, for example:
PANORAMA_MASTER_PASSWORD=mypasswd java -jar Panorama.war
or
docker run -e PANORAMA_MASTER_PASSWORD=mypasswd rammpeter/panorama
- If master-password is set, Panorama starts enhanced with:
- An additional menu entry "Admin login" in menu "Spec. additions"
- If you provide the password at "Admin login" then Panorama-Sampler config can be done at menu "Admin"/"Panorama-Sampler config"
- Background threads for data sampling (own thread for each snapshot of a configured target database)
- Access to GUI-function "Panorama-Sampler config" is protected by this master-password
- You may use different master-passwords at Panorama-server startup if this makes sense for you. This results in one configuration-set per master-password.
Configure data sources for sampling with Panorama-Sampler
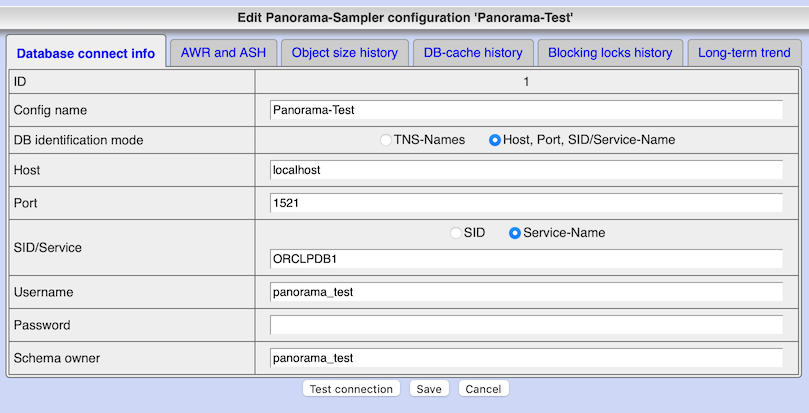
To activate sampling for your database, add it with function "Panorama-Sampler config" in menu "Spec. additions" and configure:
- TNS-Alias resp. host, port, SID/service-name
- User/password for the schema containing Panorama's tables for workload recording
- Schema name if workload tables should be created in different schema than used for connection. Important e.g. for CDB where you need to login with system account to sample workload of all PDBs
- For each of the five topics AWR/ASH, size evolution, cache-usage, blocking locks and long-term trend you can define separately:
- Activate or deactivate sampling
- Period between snapshots
- Retention time before housekeeping
- Further topic specific settings
The configured connection user needs the the following grants to work:
GRANT CONNECT, RESOURCE, CREATE VIEW
to create tables and views- Enough quota on it's default tablespace to create objects
GRANT SELECT ANY DICTIONARY
to select from dictionary tablesGRANT EXECUTE ON DBMS_LOCK
as SYS to allow execution of DBMS_LOCK.SLEEP in active session sampler.
This is needed only up to rel. 12.2, starting with 18.0 Panorama uses DBMS_SESSION.SLEEP instead of DBMS_LOCK.SLEEP.- The right to create objects in different object schema if connection user and object schema are different
GRANT SELECT ANY TABLEin addition, then PL/SQL-packages are created for the execution of sampling. If the connection user doesn't have this grant, then larger anonymous PL/SQL is executed at each snapshot instead of a package call that may result in a bit more network traffic.
The reason for need of possible anonymous PL/SQL is: you may not select from V$-tables from inside PL/SQL-packages because this right is based on role SELECT_CATALOG_ROLE and roles are not propagated to PL/SQL objects.
Choose access on Panorama-Sampler's data in Panorama's web client application
The Panorama client automatically recognizes the existence of Panorama-Sampler data during logon and offers you to choose this data. You can choose one of three options how Panorama gets access to historic workload info for this database:- Use Oracle's AWR data which requires Enterprise Edition and licensing of Diagnostics Pack for that database
- Use workload data recorded by Panorama's own sampling engine
- Don't use historic workload info, but this way Panorama's functions are strongly reduced

Please take into account that Panorama-Sampler's tables are created deferred at first snapshot execution.
This way you can choose Panorama-Sampler data at logon only after first snapshot execution.
Licensing
You may use Panorama-Sampler for free under the terms and conditions of GNU General Public License.Function volume
Until now Panorama-Sampler offers replacement for the follwing AWR views:- gv$Active_Session_History
- DBA_Hist_Active_Sess_History
- DBA_Hist_Cache_Advice
- DBA_Hist_Database_Instance
- DBA_Hist_Datafile
- DBA_Hist_Enqueue_Stat
- DBA_Hist_FileStatXS
- DBA_Hist_IOStat_Detail
- DBA_Hist_IOStat_Filetype
- DBA_Hist_Log
- DBA_Hist_Memory_Resize_Ops
- DBA_Hist_OSStat
- DBA_Hist_OSStat_Name
- DBA_Hist_Parameter
- DBA_Hist_PGAStat
- DBA_Hist_Process_Mem_Summary
- DBA_Hist_Resource_Limit
- DBA_Hist_Seg_Stat
- DBA_Hist_Service_Name
- DBA_Hist_Service_Stat
- DBA_Hist_SGAStat
- DBA_Hist_Snapshot
- DBA_Hist_SQL_Bind
- DBA_Hist_SQL_Plan
- DBA_Hist_SQLStat
- DBA_Hist_SQLText
- DBA_Hist_StatName
- DBA_Hist_Sysmetric_History
- DBA_Hist_Sysmetric_Summary
- DBA_Hist_System_Event
- DBA_Hist_SysStat
- DBA_Hist_Sys_Time_Model
- DBA_Hist_Tablespace
- DBA_Hist_Tempfile
- DBA_Hist_TempStatXS
- DBA_Hist_TopLevelCall_Name
- DBA_Hist_UndoStat
- DBA_Hist_WR_Control
Further implementation details
- For RAC-systems please add one configuration for each particular RAC-instance with instance-specific service names or given SID.
- You may use different master-passwords. This results in one configuration-set per master-password. Sampling is active only for the configuration set of the master password Panorama is started with
- Sampling cycle for the function similar to Active Session History is fixed to 1 second for short term storage (currently until next snapshot) and 10 seconds for long term storage
- Your configured connection passwords are stored in file system at Panorama server encrypted with a combination of server key (see Panorama: What about security) and your master password
Limitations compared to AWR
Sampling of active sessions
- Plan-line-ID and operation are not recorded because of missing source in v$-views
- Only top level SQL is recorded as listed by v$Session.sql_id
- I/O-Requests and amount read/written is not recorded because sampling from v$SesStat is too slow for one sample per second
Sampling of segment statistics
- 'gc cr blocks served', 'gc current blocks served' and 'chain row excess' are not available from v$SegStat
Monitoring health status of Panorama-Sampler
There is a monitoring service available athttp://<your server ip>:8080/panorama_sampler/monitor_sampler_status.
It returns a JSON buffer with a list of configured data sources with ID, name, timestamp of last successfull connect, timestamp of last error and error message.
The http return status depends on the existence of a still persisting error in any of the configured datasources (OK = 200, Error = 500).
You can use this service for observation with monitoring tools like Zabbix, Nagios. Icinga etc. .
Using other SQL scripts based on AWR and ASH
Due to the identical structure between Panorama's data and original AWR/ASH objects it becomes also possible to redirect foreign SQL scripts or software based on AWR/ASH to using Panorama's sampled data instead.This small PL/SQL snippet creates local synonyms for all AWR views (DBA_HIST_xxx) as well as for ASH (v$Active_Session_History, gv$Active_Session_History) if executed in Panorama's schema. If there's no substitution by Panorama then the DBA_HIST_xxx-synonyms are directed to a non existing object, this way causing an error at access instead of possible license violation.
In result you may run your your SQLs in Panorama's schema with all access an DB_HIST_xxx and ASH views redirected to Panorama's data or causing errors.
SET SERVEROUTPUT ON;
BEGIN
FOR Rec IN (SELECT v.View_Name, p.Object_Name Panorama_Name
FROM DBA_Views v
LEFT OUTER JOIN (SELECT /*+ NO_MERGE */ Object_Name
FROM User_Objects
WHERE Object_Name LIKE 'PANORAMA_%'
) p ON p.Object_Name = REPLACE(v.View_Name, 'DBA_HIST_', 'PANORAMA_')
WHERE v.View_Name LIKE 'DBA_HIST_%' AND v.Owner = 'SYS'
ORDER BY Panorama_Name NULLS FIRST, v.View_Name
)
LOOP
IF Rec.Panorama_Name IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Not substituted by Panorama, redirecting synonym to not existing object: '||Rec.View_Name);
EXECUTE IMMEDIATE 'CREATE OR REPLACE SYNONYM '||Rec.View_Name||' FOR NOT_SUBSTITUTED';
ELSE
DBMS_OUTPUT.PUT_LINE('Substituted by Panorama, redirecting synonym '||Rec.View_Name||' to '||Rec.Panorama_Name);
EXECUTE IMMEDIATE 'CREATE OR REPLACE SYNONYM '||Rec.View_Name||' FOR '||Rec.Panorama_Name;
END IF;
END LOOP;
DBMS_OUTPUT.PUT_LINE('Substituted by Panorama, redirecting synonym GV$ACTIVE_SESSION_HISTORY to PANORAMA_V$ACTIVE_SESS_HISTORY');
EXECUTE IMMEDIATE 'CREATE OR REPLACE SYNONYM GV$ACTIVE_SESSION_HISTORY FOR PANORAMA_V$ACTIVE_SESS_HISTORY';
DBMS_OUTPUT.PUT_LINE('Substituted by Panorama as view V$ACTIVE_SESSION_HISTORY on PANORAMA_V$ACTIVE_SESS_HISTORY');
EXECUTE IMMEDIATE 'CREATE OR REPLACE VIEW V$ACTIVE_SESSION_HISTORY AS
SELECT * FROM PANORAMA_V$ACTIVE_SESS_HISTORY
WHERE Inst_ID = SYS_CONTEXT(''USERENV'', ''INSTANCE'')';
END;
/